Parallel ML Experimentation leveraging MinIO & lakeFS

Introduction
This post was written in collaboration with Iddo Avneri from lakeFS.
Managing the growing complexity of ML models and the ever-increasing volume of data has become a daunting challenge for ML practitioners. Efficient data management and data version control are now critical aspects of successful ML workflows.
In this blog post, we delve into the power of parallel ML - running experimentation in parallel with different parameters (for example, using different optimizers, or using a different number of epochs) and explore how lakeFS and MinIO can supercharge your ML experiments and streamline your development pipeline. By leveraging the capabilities of lakeFS, an open-source data versioning tool, and MinIO, a high-performance object storage solution, you can harness the full potential of parallel ML without compromising on performance or scalability.
MinIO provides a unique set of advantages that make it an ideal choice for ML workloads. As an object store, MinIO offers exceptional scalability, enabling you to seamlessly handle large volumes of data generated by ML experiments. Its distributed architecture ensures high availability and fault tolerance, allowing you to process ML workloads with minimal downtime. Moreover, MinIO's compatibility with the S3 API makes it easy to integrate with various ML frameworks and tools, facilitating a smooth workflow across your ML ecosystem. Additionally, MinIO’s performance characteristics are a perfect compliment to the demands of AI/ML workloads. MinIO’s GETs/PUTs results exceed 325 GiB/sec and 165 GiB/sec on 32 nodes of NVMe drives and a 100GbE network. Its combination of chip-level acceleration, atomic metadata and Golang/Golang Assembly code enable it to fly on commodity hardware pushing the bottleneck to the network bandwidth. More importantly, MinIO’s performance covers the entire range of object sizes from the smallest (4KB) to the largest (50 TiB).
One of the key advantages of combining MinIO with lakeFS is the ability to achieve parallelism without incurring additional storage costs. lakeFS leverages a unique approach (zero clone copies), where different versions of your ML datasets and models are efficiently managed without duplicating the data.
Throughout this article, we provide a step-by-step guide, accompanied by a Jupyter notebook, to demonstrate how these tools work together to enhance your ML workflows. Whether you're a data scientist, ML engineer, or AI enthusiast, this blog will equip you with the knowledge and tools needed to leverage parallel ML effectively, accelerate your model development process, and optimize your storage utilization.
Stay tuned for the upcoming sections, where we'll cover:
- Importing data into a lakeFS Repository from a MinIO bucket
- Running parallel ML experiments with lakeFS and MinIO with different parameters (for example, using different optimizers, or using a different number of epochs)
- Comparing and evaluating the results
By the end of this blog post, you'll have a comprehensive understanding of how lakeFS and MinIO revolutionize the way you manage your ML data, streamline your experimentation process, and facilitate seamless collaboration within your ML team, all while maximizing the efficiency of your storage infrastructure.
Step 1: Setup
We will be utilizing a prepackaged environment (Docker containers) that includes MinIO, lakeFS, Jupyter notebook and Spark. You can read more about the example in this git repository.
Clone the repo:
And bring the environment up:
The first time you bring up the environment, it might take up to 20–30 minutes to come up, depending on the dependencies (no pun intended). The second time, it will take a few seconds 🙂
Once you brought up the environment, you can log in to Jupyter, lakeFS and MinIO using the links and passwords referenced in the git repository readme. We will be using the `ML Experimentation/Reproducibility 01 (Dogs)` notebook throughout this example (in the Jupyter UI). The notebook starts with setting up the environment (for example, configuring lakeFS, MinIO, TensorFlow, etc.). You are welcome to jump to the

section and run all the cells above it:
Once completed, everything is installed, and we are ready to start using lakeFS on top of MinIO.
Step 2: Zero clone import
We will need a dataset to work with.
In this case, our MinIO server has some prepopulated sample data we will import into lakeFS. Specifically, we use the Stanford dogs data set, which is located in the sample-data bucket within MinIO.
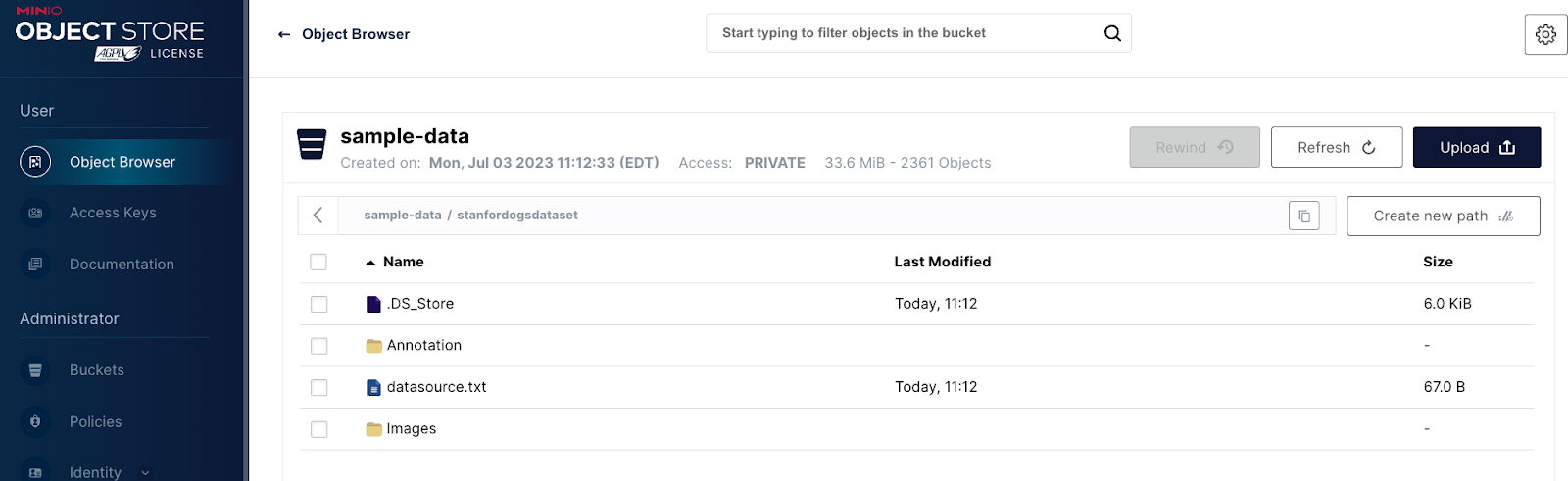
We will import the data from MinIO to the lakeFS repository. It is worth noting that the import is a zero clone operation i.e., none of the data will be actually copied over. However, you will be able to access the data and version it going forward with lakeFS.
Once you run the command below, which is in the notebook.
Log into lakeFS and view the content of the repository:
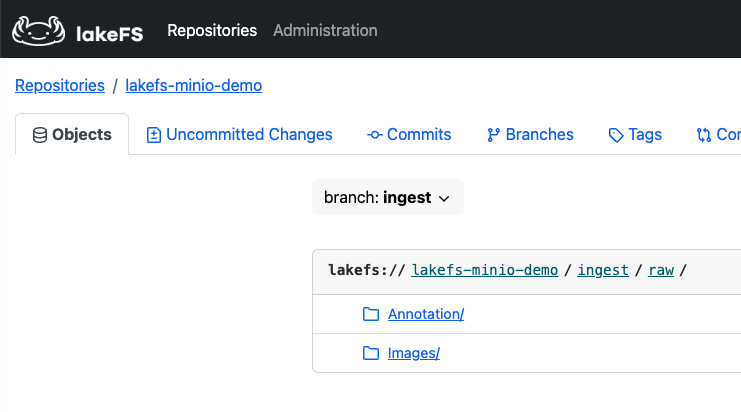
Diving in
To better understand the lakeFS / MinIO integration. Let’s examine further the content of the buckets in MinIO.
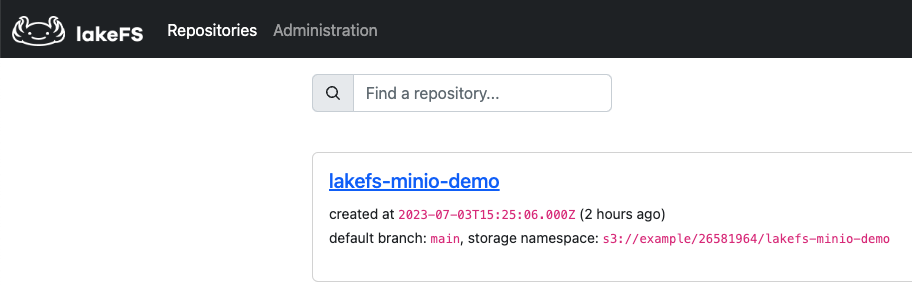
On top of the sample-data bucket we imported, the lakeFS repository also sits on top of a MinIO bucket, in my case s3://example/26581964/lakefs-minio-demo (as specified in the storage namespace below)
Let’s look at the content of that bucket inside MinIO:
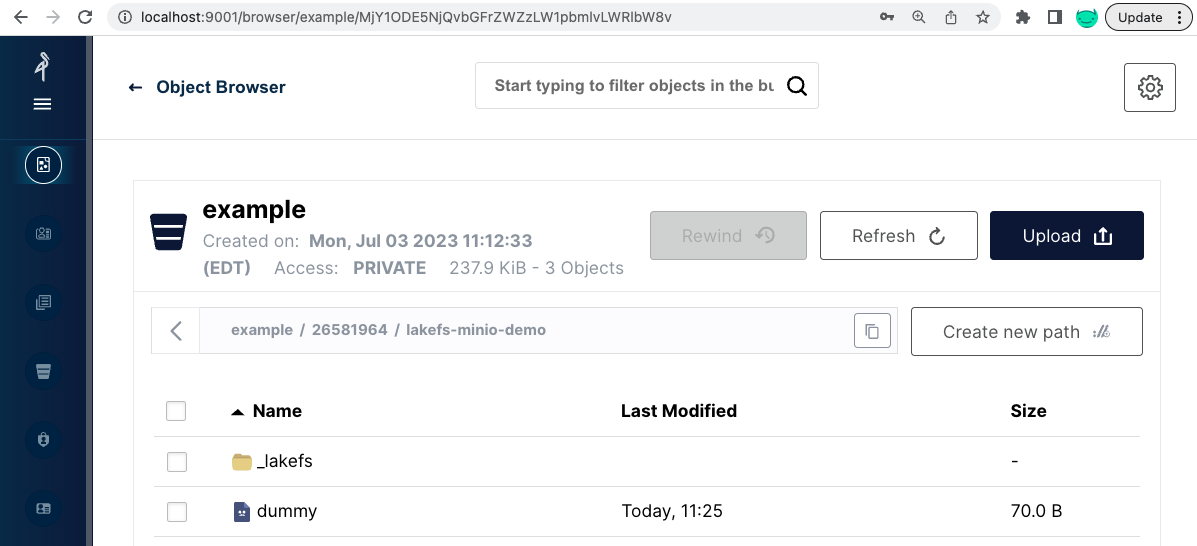
It includes a single dummy 70B file and a _lakefs directory. This dummy file was created when lakeFS created the repository, making sure we have permissions to write into the bucket. Even though we imported thousands of files, the _lakefs path includes only 2 files:
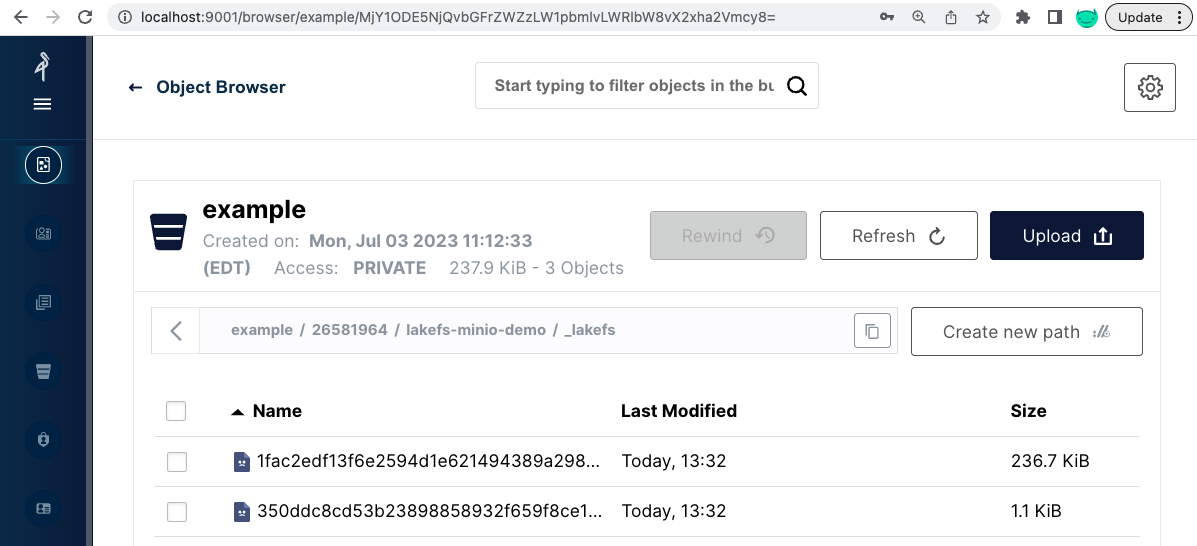
These are only references (ranges / metaranges) to the original locations of the files we imported.
However, going forward, when we write new objects via lakeFS, the new files will be sitting in the directory and not in the original directory which we imported from.
Step 3: Branching and parallel ML Experiments
Up to this point, we created a lakeFS repository and imported data from MinIO into that repository within an ingest branch. Now with the data imported, we will create a branch for each experiment and run different experiments, in isolation, with slightly different parameters:
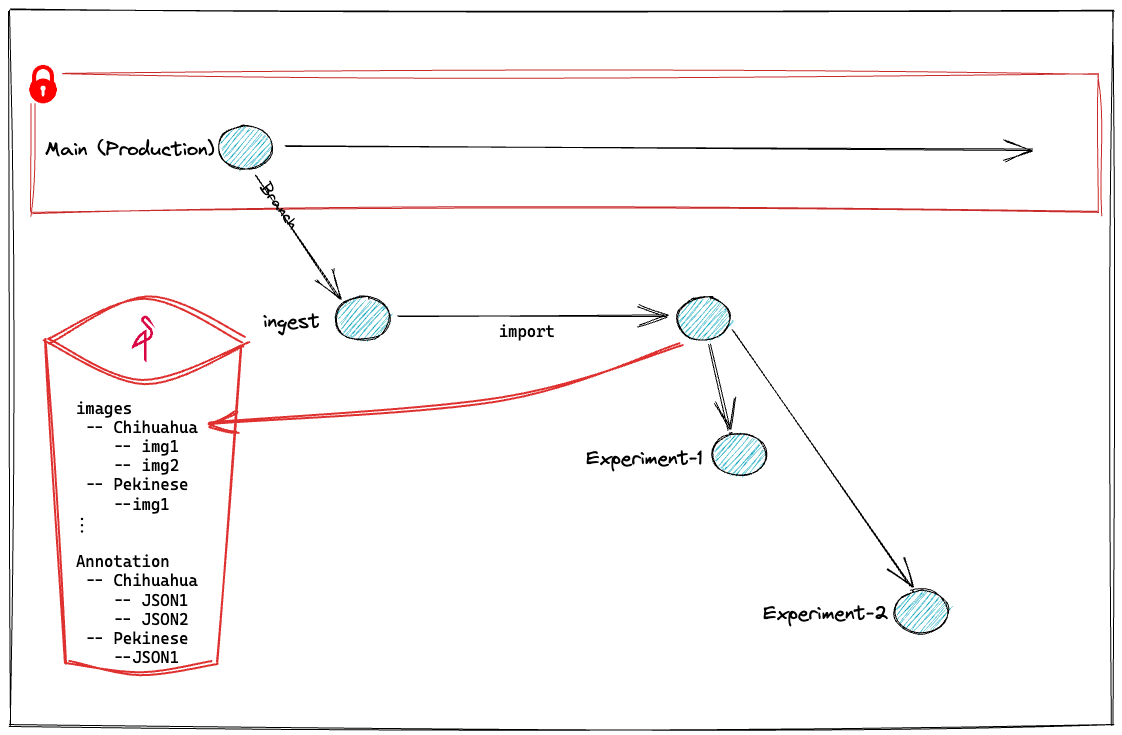
Following the notebook in the next few cells, we will set the parameters of the first experiment, train the model, run predictions, and save the specific model configuration and artifacts on its branch.
These steps will include (among others) creating the branches (such as experiment-1) from the ingest branch which we imported the data into:
For example, once we finalize the first experiment, the experiment-1 branch will look like this:
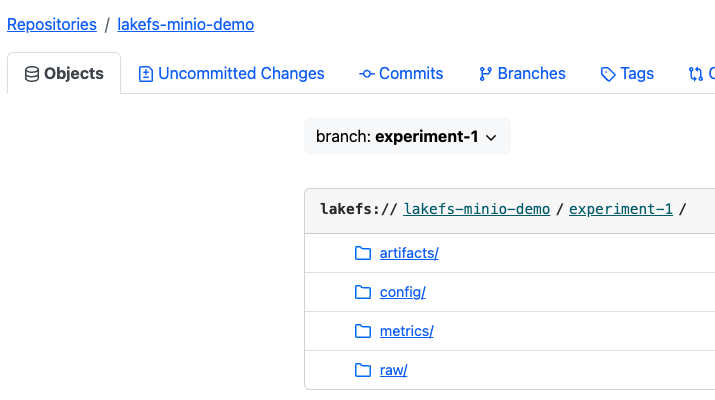
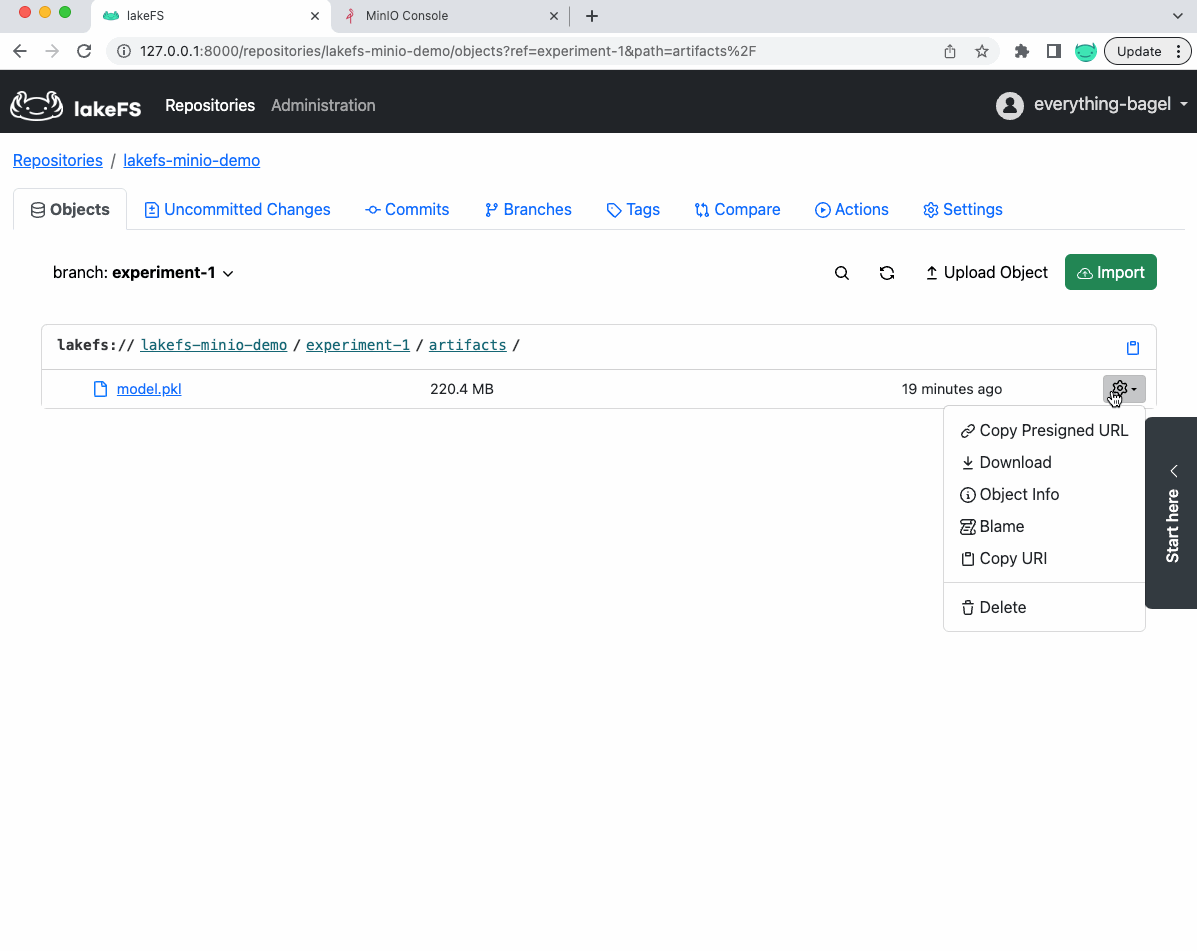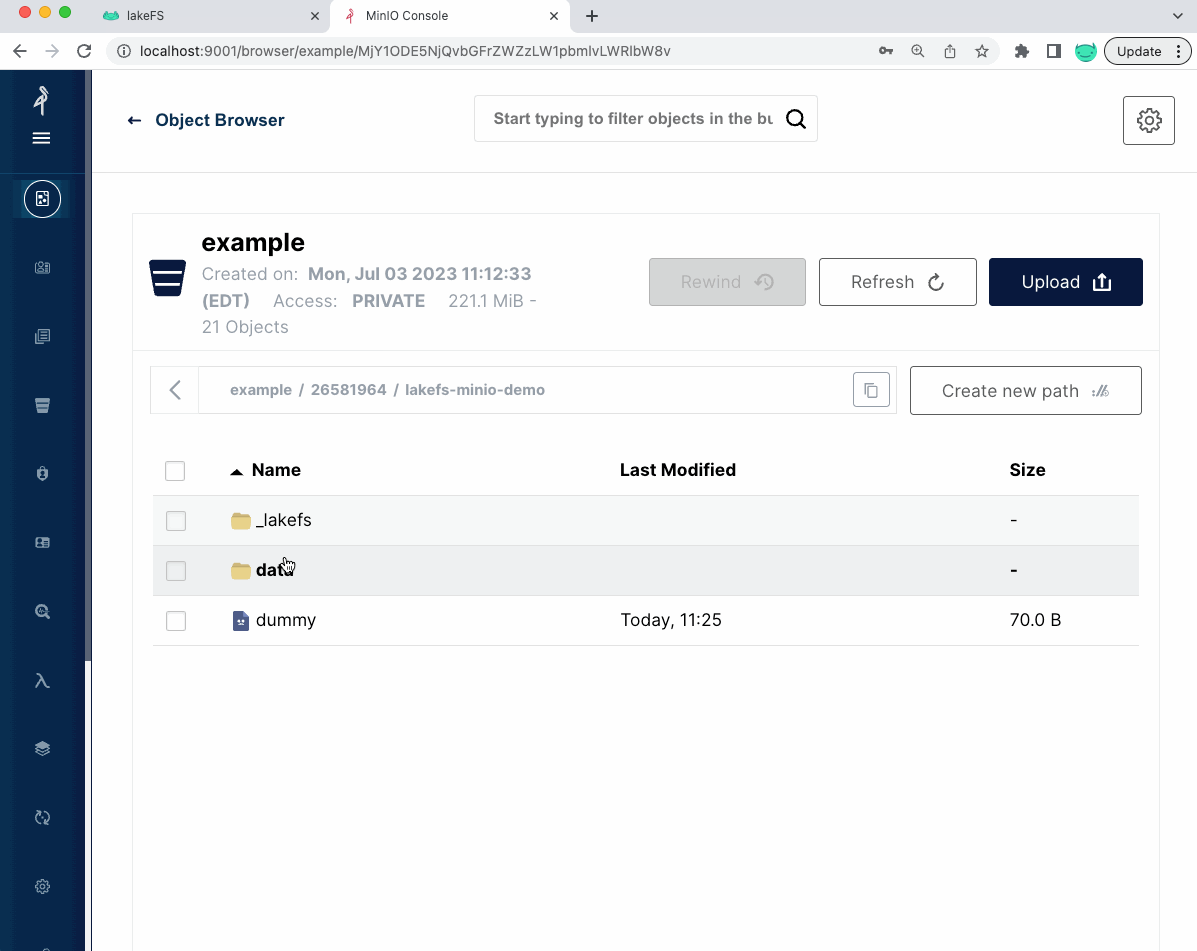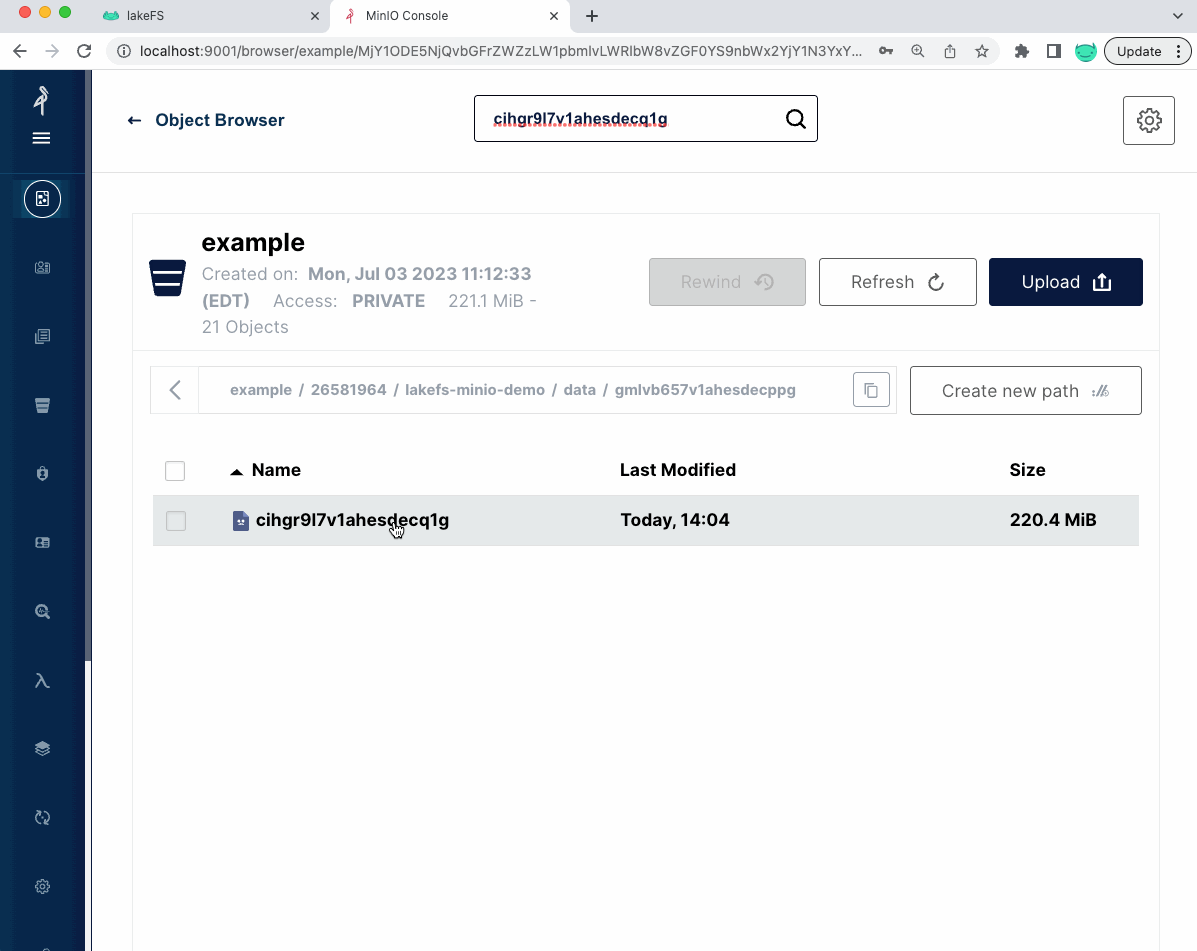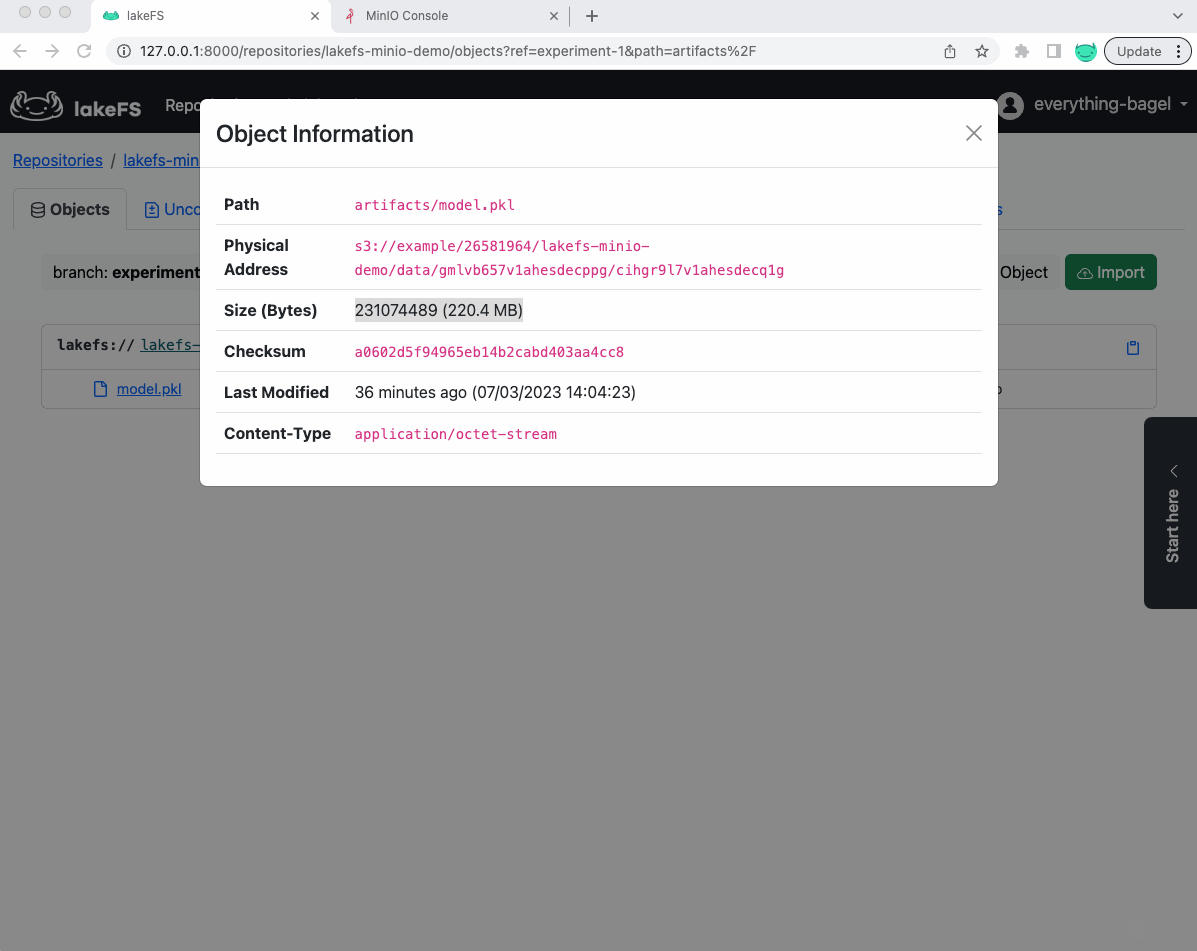
artifacts: contains the model .pkl file.
config: contains the parameters' configuration for this model.
metrics: contains loss and accuracy metrics of the model (in this example, we will use sparse categorical cross entropy to measure the loss)
raw: contains the original data sets the model was trained against.
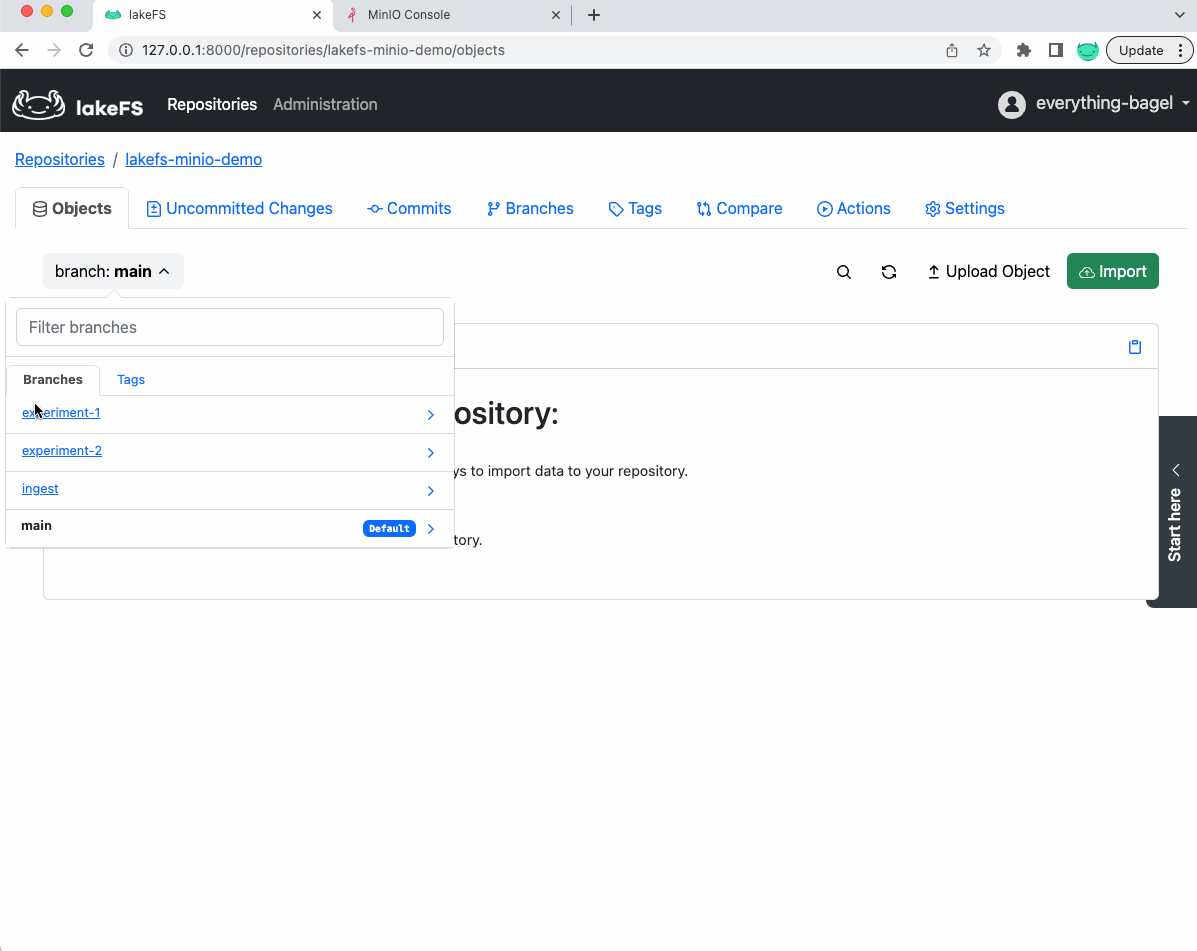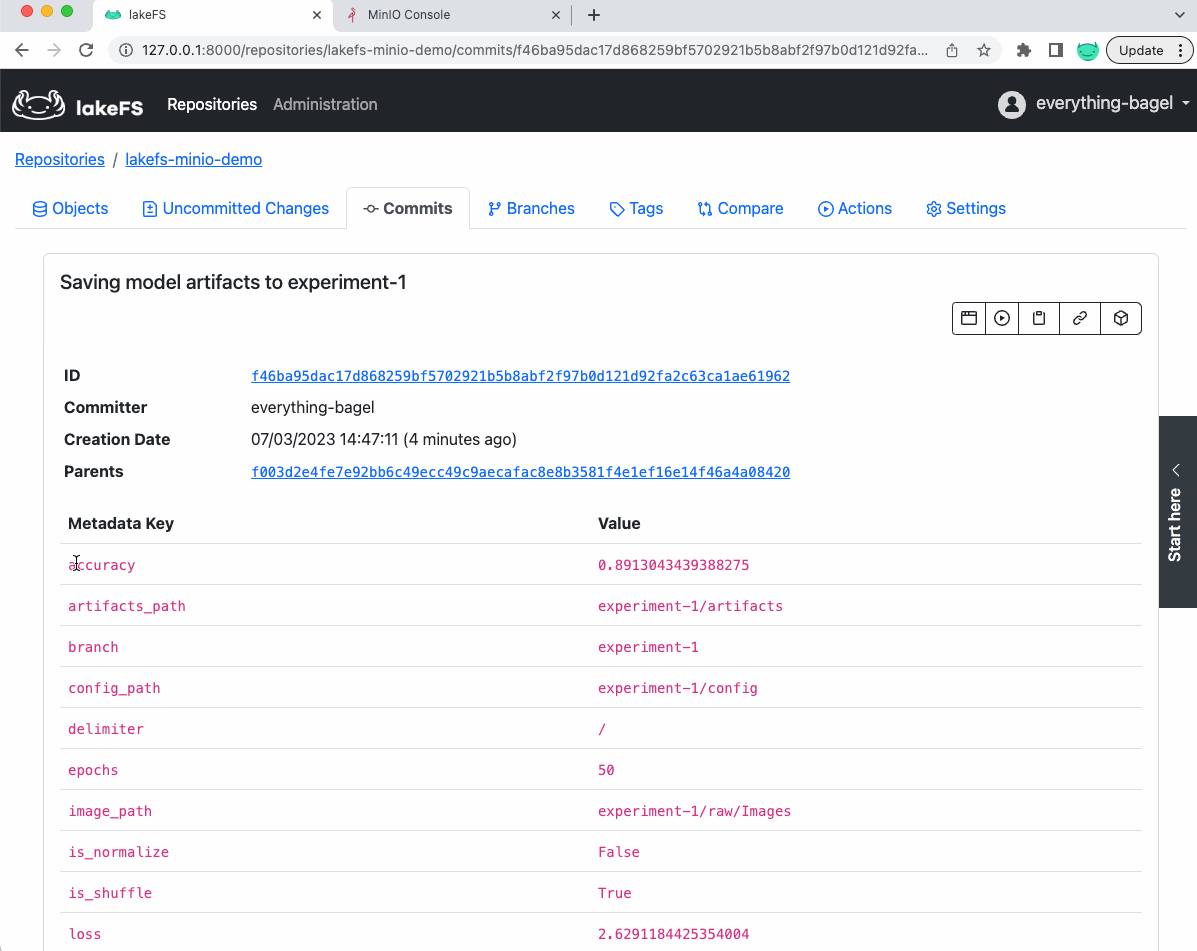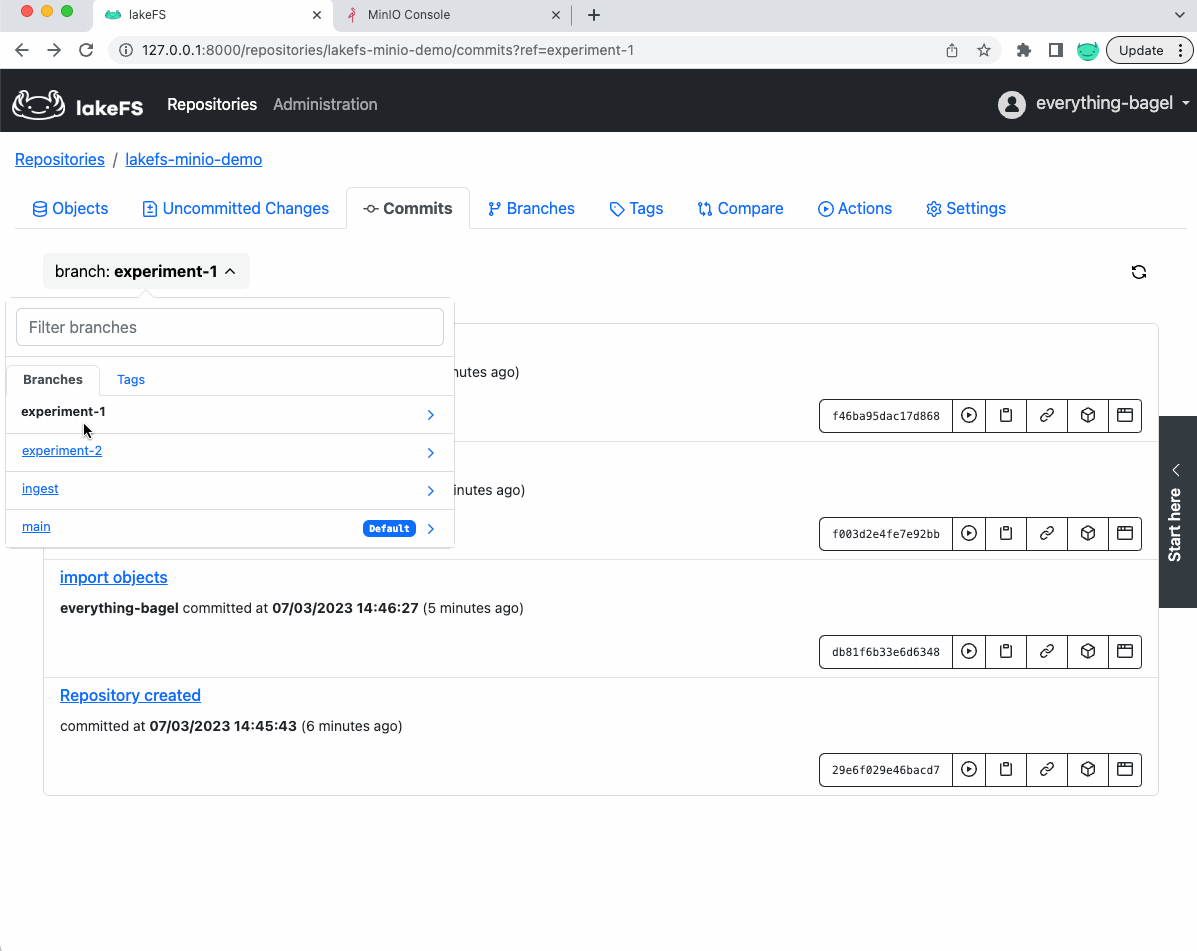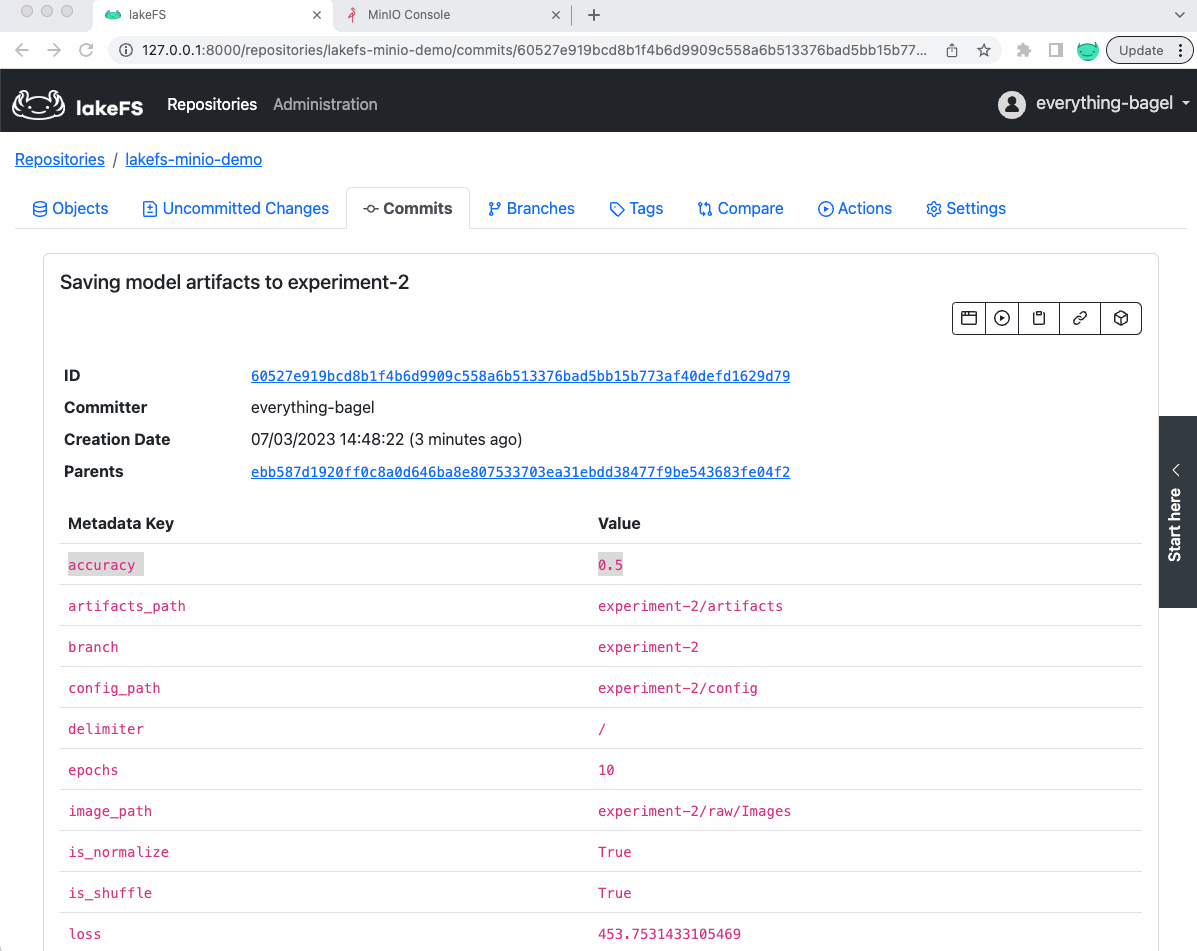
In other words, we versioned in this single commit (shown below) the dataset, the model, its configuration, and accuracy in an easily reproducible way.
Furthermore, if we look at the commit in lakeFS saving the model, we will see th metrics and parameters as metadata of the commit (which can be used later for references):
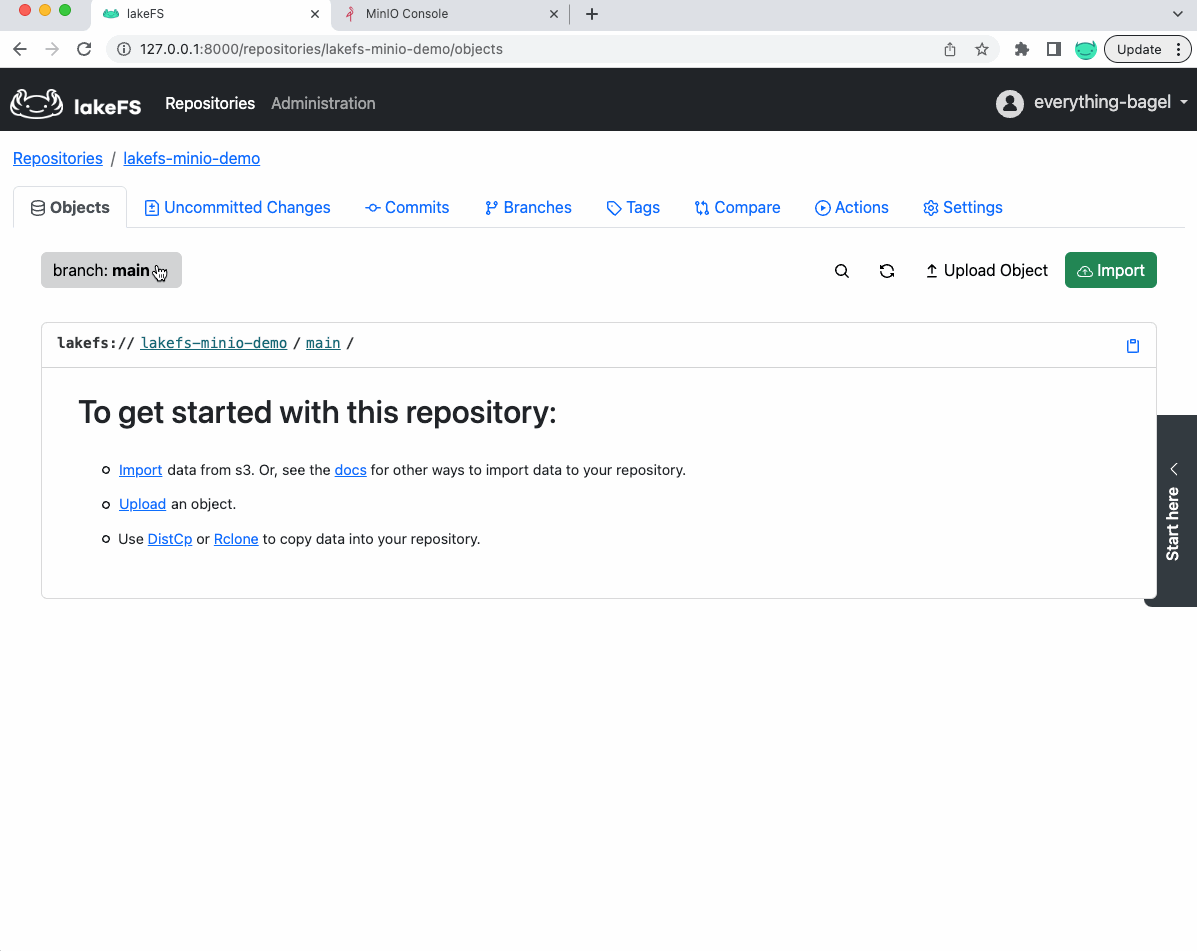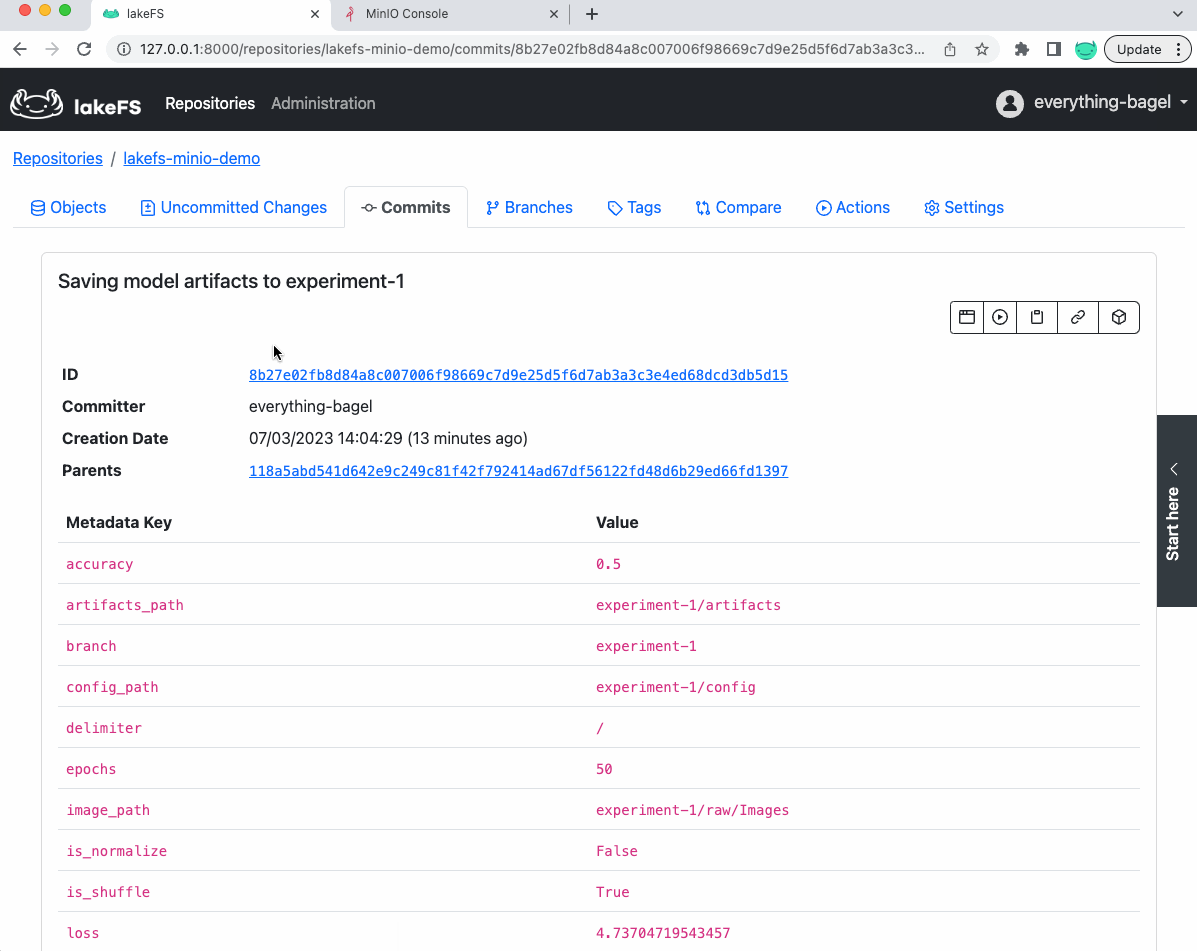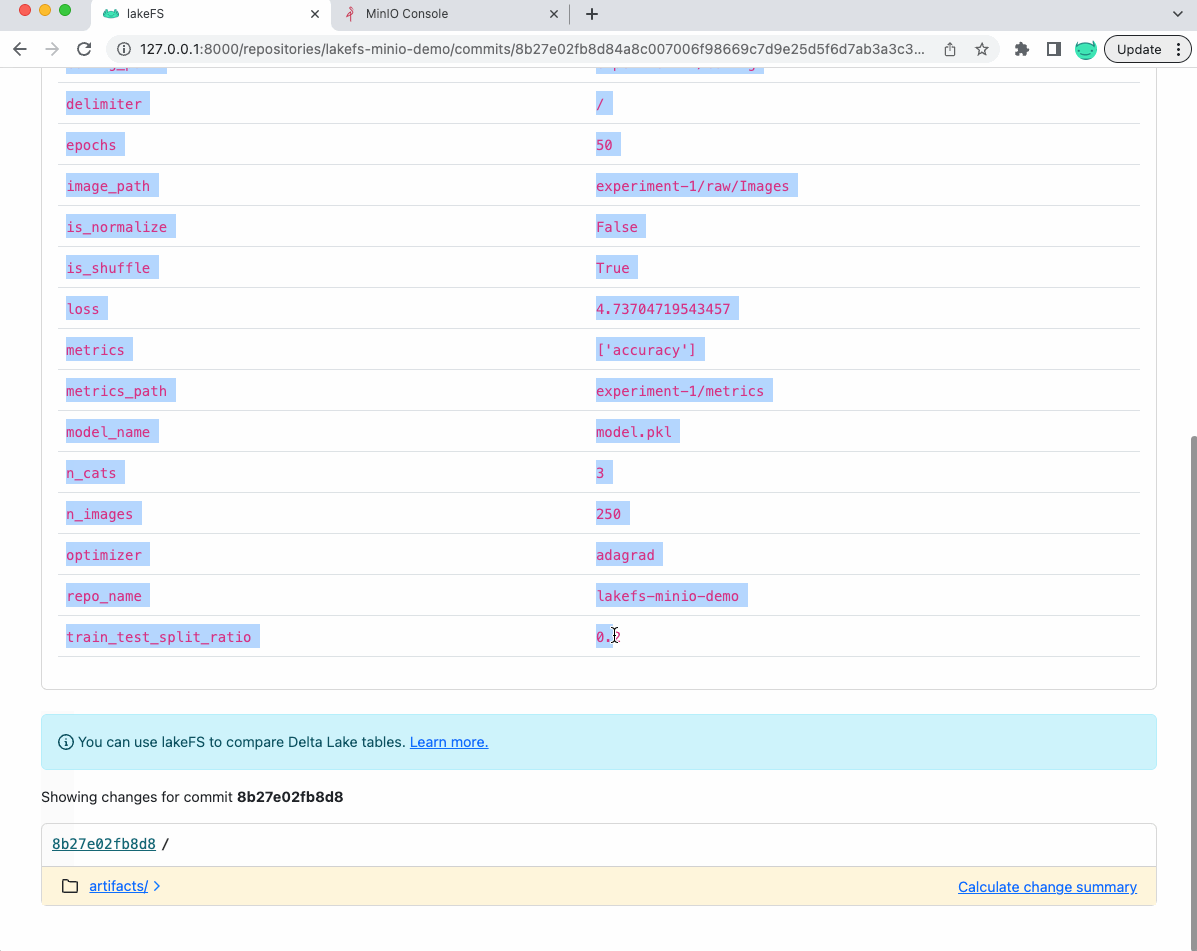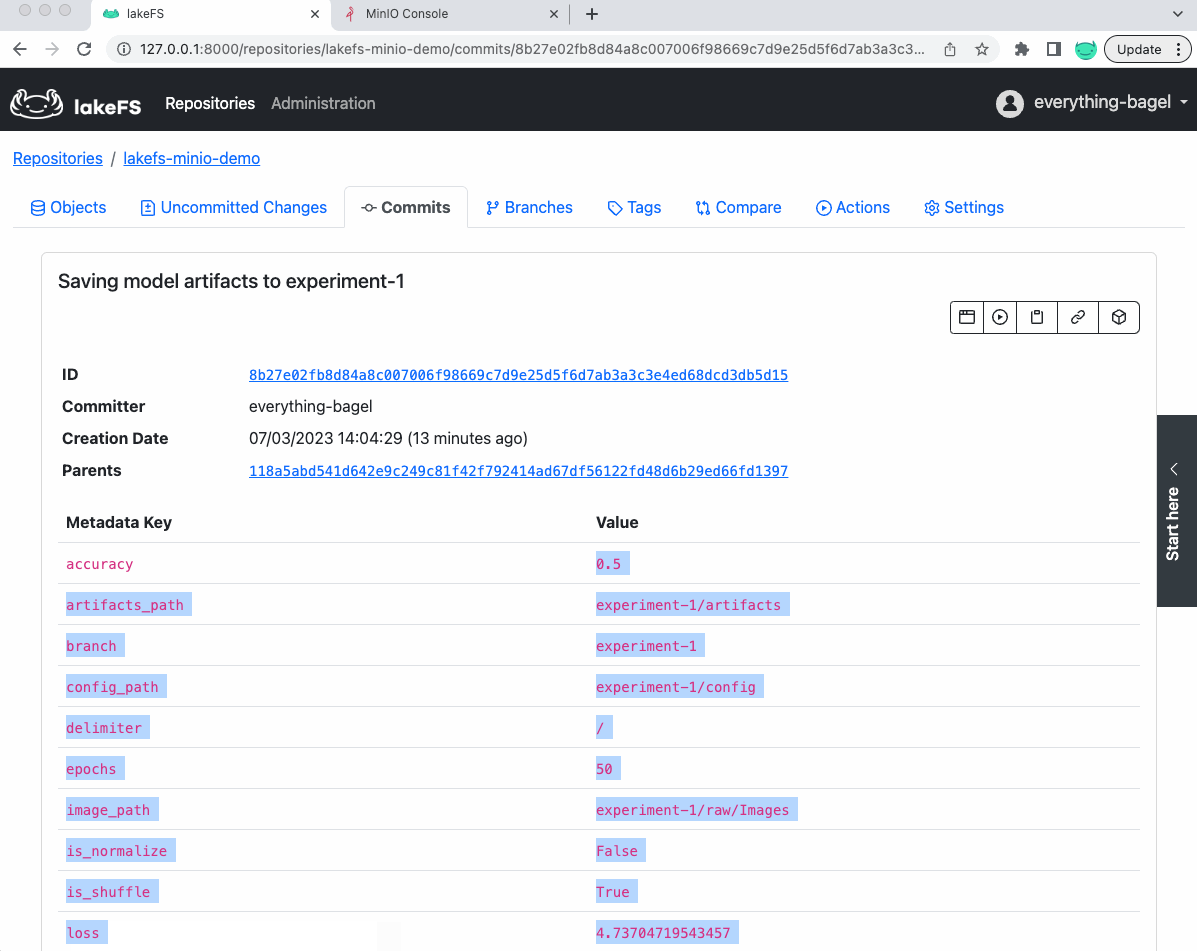
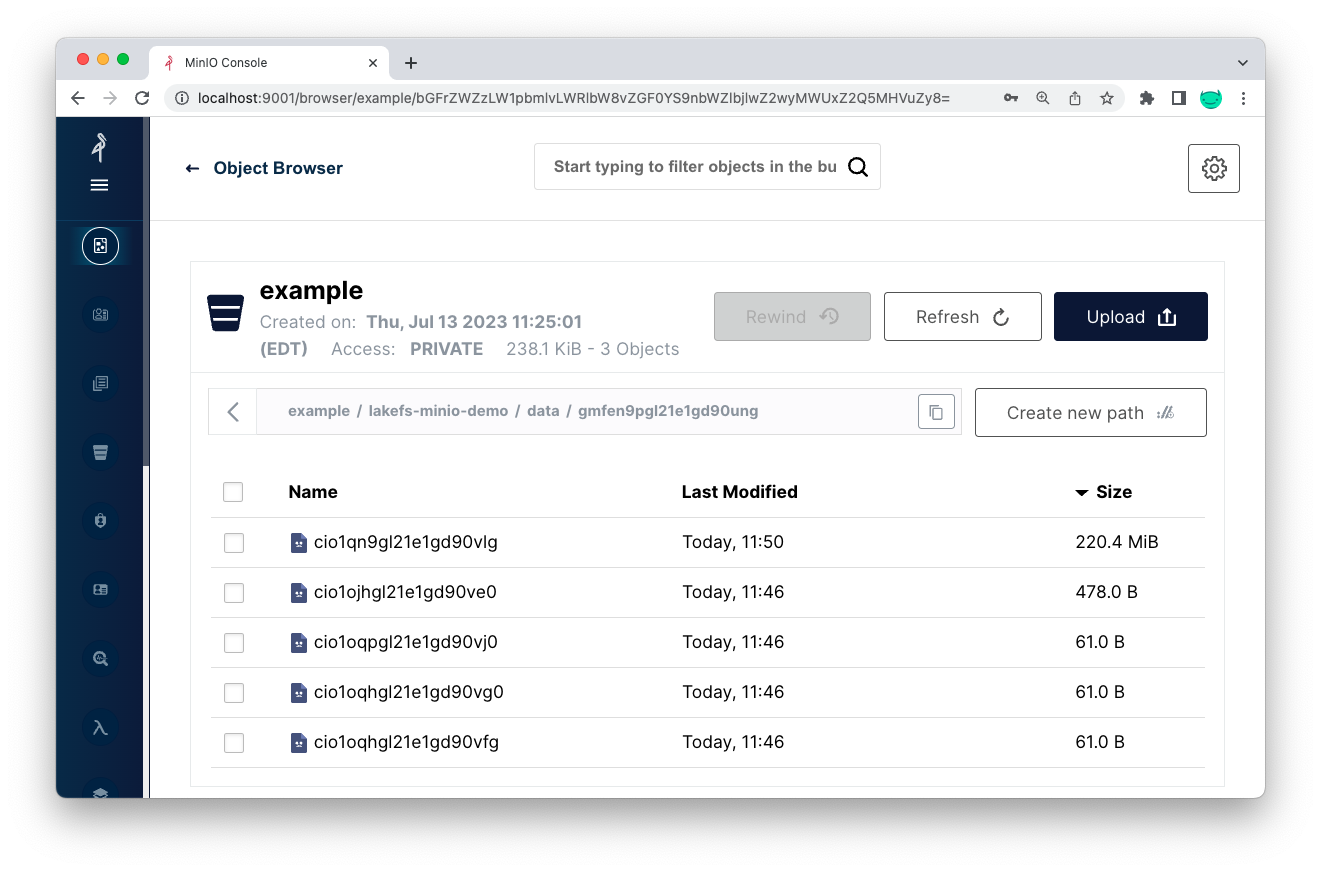
Now, let’s see how the data looks like in the underlying MinIO bucket:
In the example bucket, under the lakefs-minio-demo directory, we now have a new folder called data:
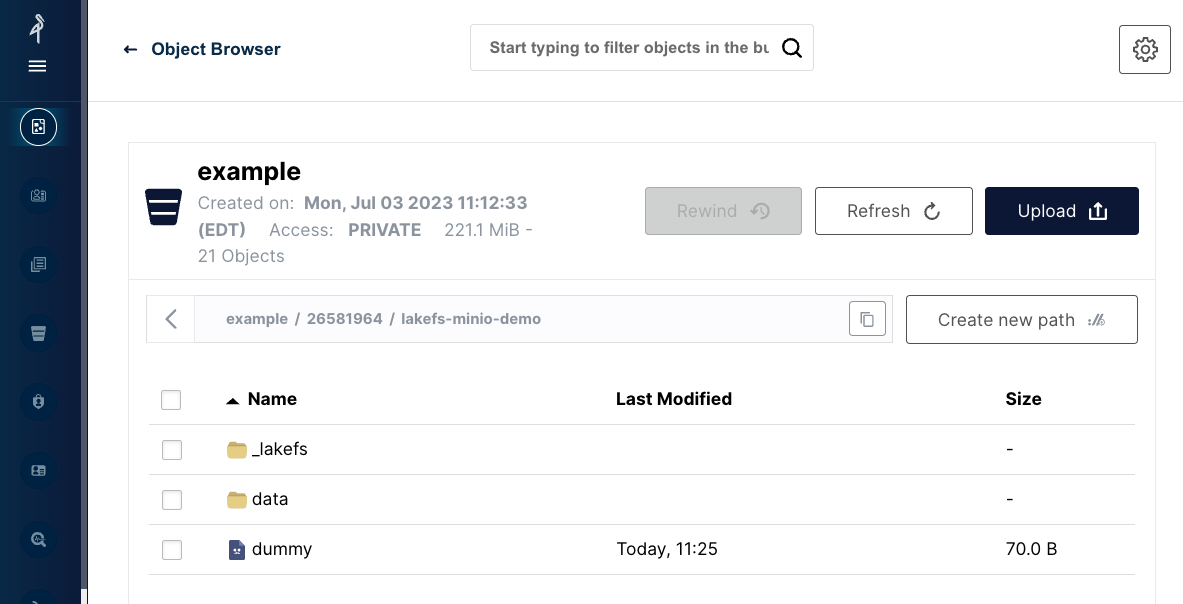
The new files we saved (such as the model .pkl file) are saved under the data path:
Pro tip
You can click on the cog-wheel next to any file in the lakeFS UI and select object-info to locate that specific file inside MinIO:
Once we have run through experiment-2, our lakeFS repository will include 2 branches, keeping the complete artifacts, data, and metrics for each experiment:
Step 4: Comparing and evaluating the results
Once both experiments have completed, we can compare them and promote, to production, the best one.
For example:
In the example above, experiment-1 is a lot more accurate; therefore, I would like to promote that one into production. Running a merge, will promote the data from that branch into my main branch:
Once again, no data is being duplicated in the underlying MinIO buckets. However, now I have a single production branch with a single reference commit, which includes the entire data set, the configuration and the performance of the model.
Want to learn more?
If you have questions about MinIO, then drop us a line at hello@min.io or join the discussion on MinIO’s general Slack channel.
If you have questions about lakeFS, then drop us a line at hello@treeverse.io or join the discussion on lakeFS’ Slack channel.